

O Prêmio Nobel de 2021 para David Card, Joshua Angrist and Guido Imbens trouxe finalmente para o holofote do grande público e da comunidade científica geral a revolução da credibilidade (Angrist & Pischke, 2010) e, também, a inferência causal (leia mais sobre esses temas aqui e aqui).
Durante grande parte da história da estatística, meras associações eram suficientes. Mas isso mudou. Por quê? Por que as ciências precisam agora olhar para a causalidade, um assunto espinhoso metafisicamente?
O entendimento da necessidade de se estipular mecanismos causais e estimá-los fica mais claro por meio de um exemplo: o Paradoxo de Simpsons, um paradoxo estatístico que surge quando focamos apenas em associações nos dados sem se preocupar com o mecanismo gerador de tais associações. Para entendê-lo, traduzi trechos do livro Glymour et al. (2016, p. 1-5). Segue a tradução abaixo.
.
Nomeado em homenagem a Edward Simpson (nascido em 1922), o estatístico que o popularizou pela primeira vez, o paradoxo refere-se à existência de dados em que uma associação estatística que vale para uma população inteira é revertida em cada subpopulação. Por exemplo, podemos descobrir que os alunos que fumam obtêm notas mais altas, em média, do que os não-fumantes. Mas quando levamos em conta a idade dos alunos, podemos descobrir que, em todas as faixas etárias, os fumantes obtêm notas mais baixas do que os não fumantes. Então, se levarmos em conta a idade e a renda, podemos descobrir que os fumantes mais uma vez tiram notas mais altas do que os não fumantes da mesma idade e renda. As reversões podem continuar indefinidamente, alternando para frente e para trás à medida que consideramos mais e mais atributos. Neste contexto, queremos decidir se fumar provoca aumentos de notas e em que direção e em quanto, mas parece impossível obter as respostas dos dados.
No exemplo clássico usado por Simpson (1951), um grupo de pacientes doentes tem a opção de experimentar um novo remédio. Uma porcentagem menor de pacientes se recuperou entre aqueles que tomaram o remédio em relação àqueles que não tomaram. No entanto, quando partimos por gênero, vemos que mais homens que tomam o remédio se recuperam do que homens que não estão tomando o remédio, e mais mulheres que tomam o remédio se recuperam do que mulheres que não estão tomando o remédio! Em outras palavras, o remédio parece ajudar homens e mulheres, mas prejudica a população em geral. Parece absurdo, ou mesmo impossível – e é por isso que, é claro, é considerado um paradoxo. Algumas pessoas acham difícil acreditar que os números possam ser combinados dessa maneira. Para torná-lo crível, então, considere o seguinte exemplo:
Registramos as taxas de recuperação de 700 pacientes que tiveram acesso ao medicamento. Um total de 350 pacientes optou por tomar o remédio e 350 pacientes não. Os resultados do estudo são mostrados na Tabela 1.

A primeira linha mostra o resultado para pacientes do sexo masculino; a segunda linha mostra o resultado para pacientes do sexo feminino; e a terceira linha mostra o resultado para todos os pacientes, independentemente do sexo. Em pacientes do sexo masculino, os usuários do remédio tiveram uma melhor taxa de recuperação do que aqueles que ficaram sem o remédio (93% vs. 87%). Em pacientes do sexo feminino, novamente, aqueles que tomaram o remédio tiveram uma melhor taxa de recuperação do que os que não tomaram (73% vs. 69%). No entanto, na população combinada, aqueles que não tomaram o remédio tiveram uma melhor taxa de recuperação do que aqueles que o fizeram (83% vs. 78%).
Os dados parecem dizer que se soubermos o sexo do paciente – masculino ou feminino – podemos prescrever o remédio, mas se o sexo for desconhecido, não devemos! Obviamente, essa conclusão é ridícula. Se o remédio ajuda homens e mulheres, deve ajudar qualquer um; nossa falta de conhecimento do sexo do paciente não pode tornar o remédio prejudicial.
Diante dos resultados deste estudo, então, um médico deve prescrever o remédio para uma mulher? Um homem? Um paciente de sexo desconhecido? Ou considere um formulador de políticas que está avaliando a eficácia geral do medicamento na população. Ele/ela deve usar a taxa de recuperação para a população em geral? Ou ele/ela deve usar as taxas de recuperação para as subpopulações de gênero?
A resposta está longe de ser encontrada em estatísticas simples. Para decidir se o remédio irá prejudicar ou ajudar um paciente, primeiro temos que entender a história por trás dos dados – o mecanismo causal que levou ou gerou os resultados que vemos. Por exemplo, suponha que soubéssemos de um fato adicional: o estrogênio tem um efeito negativo na recuperação, de modo que as mulheres são menos propensas a se recuperar do que os homens, independentemente do remédio. Além disso, como podemos ver pelos dados, as mulheres são significativamente mais propensas a tomar o remédio do que os homens. Assim, a razão pela qual o remédio parece ser prejudicial em geral é que, se selecionarmos um usuário do remédio aleatoriamente, essa pessoa tem mais probabilidade de ser uma mulher e, portanto, menos probabilidade de se recuperar do que uma pessoa aleatória que não toma o remédio. Em outras palavras, ser mulher é uma causa comum tanto de uso do remédio quanto de falha na recuperação. Portanto, para avaliar a eficácia, precisamos comparar indivíduos do mesmo sexo, garantindo assim que qualquer diferença nas taxas de recuperação entre aqueles que tomam o remédio e aqueles que não o fazem não é atribuível ao estrogênio. Isso significa que devemos consultar os dados segregados, que nos mostram inequivocamente que o remédio é útil. Isso corresponde à nossa intuição, que nos diz que os dados segregados são “mais específicos”, portanto, mais informativos do que os dados não segregados.
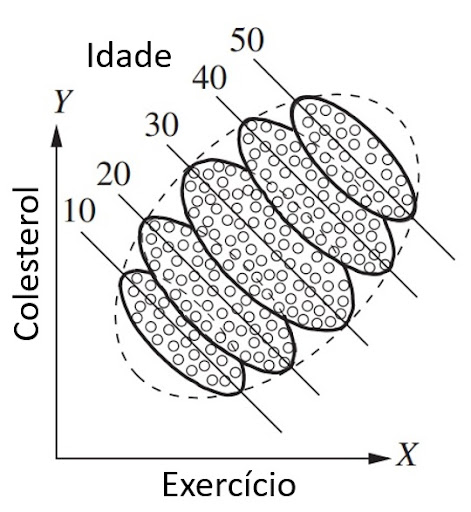
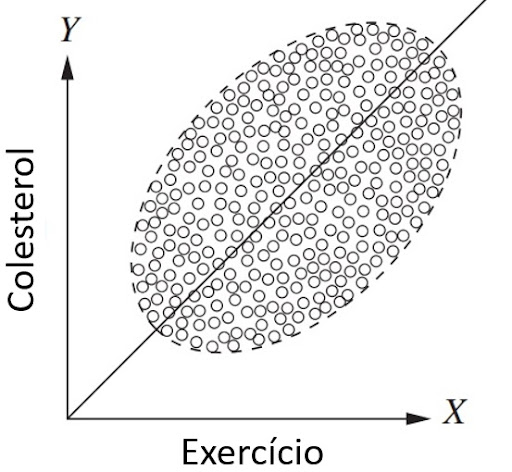
Com alguns ajustes, podemos ver como a mesma reversão pode ocorrer em um exemplo contínuo. Considere um estudo que mede exercícios semanais e colesterol em várias faixas etárias. Quando plotamos o exercício no eixo X e o colesterol no eixo Y e segregamos por idade, como na Figura 1, vemos que há uma tendência geral de queda em cada grupo; quanto mais os jovens se exercitam, menor é o colesterol, e o mesmo se aplica a pessoas de meia-idade e idosos. Se, no entanto, usarmos o mesmo gráfico de dispersão, mas não segregarmos por gênero (como na Figura 2), veremos uma tendência geral ascendente; quanto mais uma pessoa se exercita, maior é o seu colesterol. Para resolver esse problema, voltamos mais uma vez à história por trás dos dados. Se soubermos que as pessoas mais velhas, que são mais propensas a se exercitar (Figura 1), também são mais propensas a ter colesterol alto, independentemente do exercício, a reversão é facilmente explicada e facilmente resolvida. A idade é uma causa comum tanto do tratamento quanto do resultado (colesterol). Portanto, devemos analisar os dados segregados por idade para comparar pessoas da mesma idade e, assim, eliminar a possibilidade de que os praticantes de alta atividade em cada grupo que examinamos tenham maior probabilidade de ter colesterol alto devido à idade, e não devido ao exercício.
No entanto, e isso pode surpreender alguns leitores, dados segregados nem sempre dão a resposta correta. Suponha que analisamos os mesmos números do nosso primeiro exemplo de uso do remédio e recuperação, em vez de registrar o sexo dos participantes, a pressão arterial dos pacientes foi registrada no final do experimento. Nesse caso, sabemos que o remédio afeta a recuperação ao baixar a pressão arterial de quem a toma – mas, infelizmente, também tem um efeito tóxico. No final de nosso experimento, recebemos os resultados mostrados na Tabela 2. (A Tabela 2 é numericamente idêntica à Tabela 1, com exceção dos rótulos das colunas, que foram trocados).

Agora, você recomendaria o remédio a um paciente?
Mais uma vez, a resposta decorre da forma como os dados foram gerados. Na população em geral, o remédio pode melhorar as taxas de recuperação devido ao seu efeito sobre a pressão arterial. Mas nas subpopulações – o grupo de pessoas cuja PA (pressão arterial) pós-tratamento é alta e o grupo cuja PA pós-tratamento é baixa – nós, é claro, não veríamos esse efeito; veríamos apenas o efeito tóxico do remédio.
Como no exemplo do gênero, o objetivo do experimento era avaliar o efeito geral do tratamento nas taxas de recuperação. Mas neste exemplo, como a redução da pressão arterial é um dos mecanismos pelos quais o tratamento afeta a recuperação, não faz sentido separar os resultados com base na pressão arterial. (Se tivéssemos registrado a pressão arterial dos pacientes antes do tratamento, e se fosse a PA que afetasse o tratamento, e não o contrário, seria uma história diferente.) Então consultamos os resultados para a população em geral, descobrimos que o tratamento aumenta a probabilidade de recuperação e decidimos que devemos recomendar o tratamento. Notavelmente, embora os números sejam os mesmos nos exemplos de gênero e pressão arterial, o resultado correto está nos dados segregados para o primeiro e nos dados agregados para o segundo.
Nenhuma das informações que nos permitiram tomar uma decisão de tratamento – nem o momento das medições, nem o fato de o tratamento afetar a pressão arterial e nem o fato de a pressão arterial afetar a recuperação – foi encontrada nos dados. De fato, como os livros didáticos de estatística tradicionalmente (e corretamente) alertam os alunos, correlação não é causalidade [sobre o assunto recomenda-se esse texto], portanto, não há método estatístico que possa determinar a história causal apenas a partir dos dados. Consequentemente, não existe um método estatístico que possa auxiliar na nossa decisão.
No entanto, os estatísticos interpretam os dados com base em suposições causais desse tipo o tempo todo. Na verdade, a natureza paradoxal de nosso exemplo inicial de gênero do problema de Simpson é derivado de nossa forte convicção de que o tratamento não pode afetar o sexo. Se pudesse, não haveria paradoxo, já que a história causal por trás dos dados poderia facilmente assumir a mesma estrutura do nosso exemplo de pressão arterial. Por mais trivial que a suposição “tratamento não causa sexo” possa parecer, não há como testá-la nos dados, nem há como representá-la na matemática das estatísticas padrão. De fato, não há como representar qualquer informação causal em tabelas de contingência (como as Tabelas 1 e 2), nas quais a inferência estatística geralmente se baseia.
.
Ou seja, perceba que, como diz Pearl & Mackenzie (2018, p.13): “data are profoundly dumb” [“os dados são profundamente burros”]. Os métodos causais que vêm sendo desenvolvidos desde a década de 70, por exemplo com o trabalho de Donald Rubin (1974), permitiram que as ciências empíricas saíssem da linguagem do nível de associações para ir para um nível de abstração maior, que é dos contrafactuais.
Para saber mais deste mundo causal recomendo Cunningham (2021), Huntington-Klein (2021) e Morgan & Winship (2015). Além disso, caso a modelagem dos Structural Causal Models (ou “Modelos Causais Estruturais” , em tradução livre) for de interesse, recomendo Pearl & Mackenzie (2018), Glymour et al. (2016) e este texto introdutório. Espero que o presente texto tenha causado a curiosidade dos leitores e que se aprofundem cada vez mais nesse fascinante mundo da causalidade. Até a próxima.
Referências
Angrist, Joshua D., and Jörn-Steffen Pischke. “The credibility revolution in empirical economics: How better research design is taking the con out of econometrics.” Journal of economic perspectives 24.2 (2010): 3-30.
Glymour, Madelyn, Judea Pearl, and Nicholas P. Jewell. Causal inference in statistics: A primer. John Wiley & Sons, 2016.
Simpson, Edward H. “The interpretation of interaction in contingency tables.” Journal of the Royal Statistical Society: Series B (Methodological) 13.2 (1951): 238-241.
Pearl, Judea, and Dana Mackenzie. The book of why: the new science of cause and effect. Basic books, 2018.
Rubin, Donald B. “Estimating causal effects of treatments in randomized and nonrandomized studies.” Journal of educational Psychology 66.5 (1974): 688.
Cunningham, Scott. “Causal inference.” Causal Inference. Yale University Press, 2021.
Huntington-Klein, Nick. The effect: An introduction to research design and causality. Chapman and Hall/CRC, 2021.
Morgan, Stephen L., and Christopher Winship. Counterfactuals and causal inference. Cambridge University Press, 2015.
.
Leia também:
O que é uma regressão linear?
Correlação não é causalidade. Mas por quê?
Causalidade nas ciências sociais (Parte 1)
Aplicação do modelo Log-Log – Econometria com R


Deixe um comentário